The Mystery of Qwen-Image's Ignored Negative Prompts
A deep dive into why negative prompts don't work with Qwen-Image. Spoiler: it's not a bug in your workflow - the model simply doesn't support them.
Have you ever spent hours debugging a “broken” workflow, only to discover the feature you were trying to fix never existed in the first place? That’s exactly what happened to me with Qwen-Image and negative prompts. Buckle up for a journey through CFG scales, flow-matching architectures, and the art of reading documentation that doesn’t exist.
TL;DR
Qwen-Image’s negative_prompt parameter is required for the pipeline to work, but it does not exclude content from your generations. The model wasn’t trained to respond to negative conditioning like Stable Diffusion or Flux. Use positive prompt engineering instead.
The Problem: “child” in Negative, Children in Output
I was building a local image generation tool using Qwen-Image via ComfyUI, and everything was working great until I tried using negative prompts. My test case was simple:
- Prompt:
a radiant portrait of a %%(where %% is replaced with different terms) - Negative:
child - Expected: Adults regardless of the term used
- Got: Children when using “young girl” or “youngie”, completely ignoring my negative prompt
“Maybe the CFG is too low,” I thought. So I ran a proper experiment.
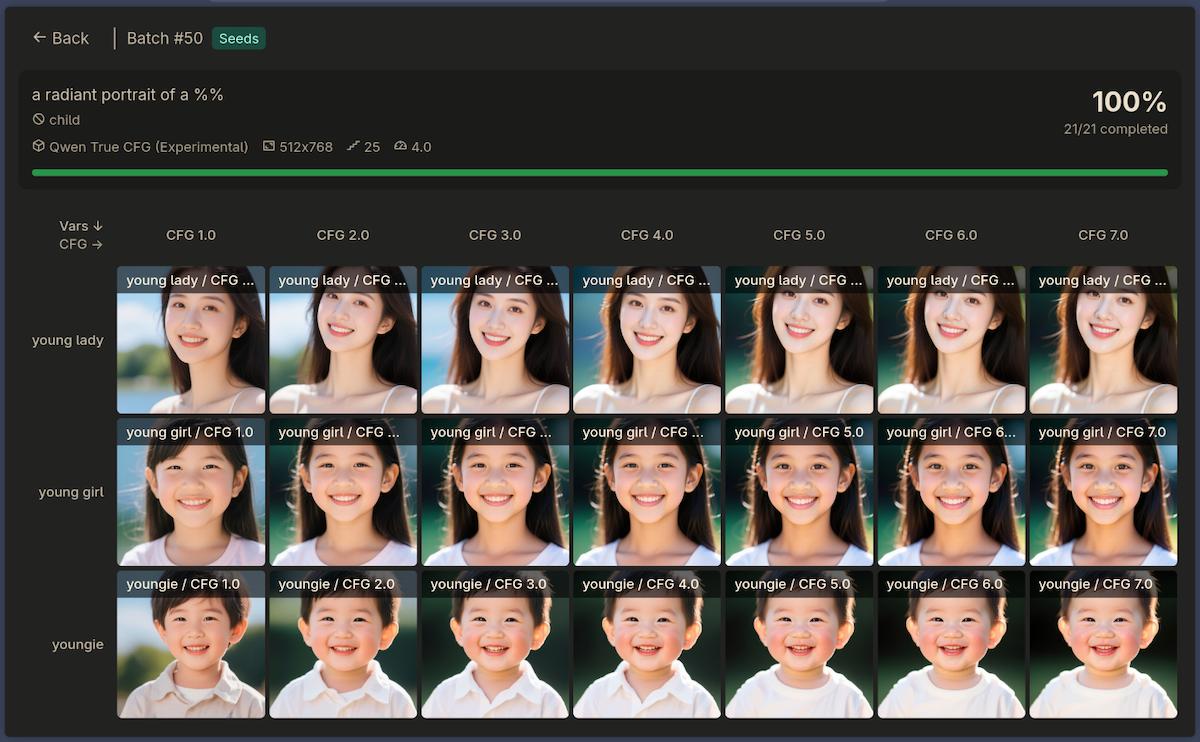
The Experiment: CFG Scale Grid Test
I created a 2D grid experiment varying both the prompt subject and the CFG scale:
| Prompt Variation | CFG Values |
|---|---|
| young lady | 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0 |
| young girl | 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0 |
| youngie | 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0 |
All with child in the negative prompt. The results?
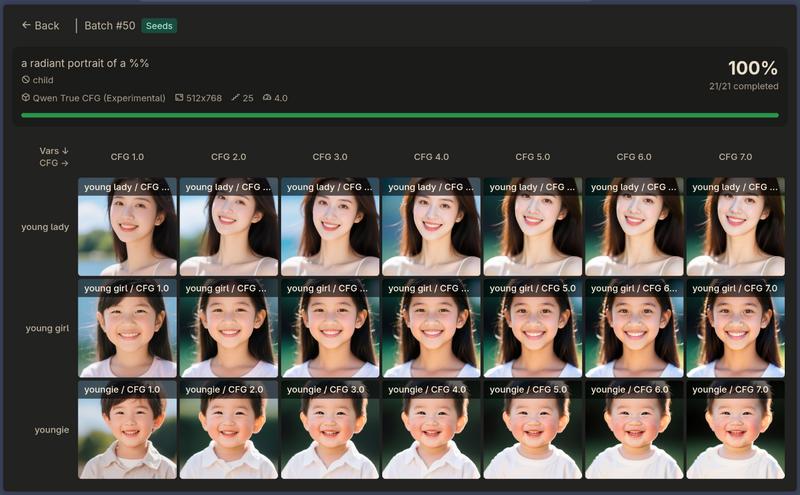
The grid experiment results: “young lady” shows adults, but “young girl” and “youngie” show children despite “child” being in the negative prompt. CFG scale from 1.0 to 7.0 makes no difference.
Zero effect across all CFG values. The “young girl” row showed children. The “youngie” row showed babies. Even at CFG 7.0, the negative prompt was completely ignored.
This wasn’t a workflow bug. Something deeper was going on.
Down the Rabbit Hole: Understanding CFG
My first hypothesis was that the standard KSampler’s cfg parameter wasn’t implementing “true” CFG for flow-matching models like Qwen-Image. The official Qwen-Image Python pipeline uses a parameter called true_cfg_scale, not just cfg.
What is CFG Anyway?
Classifier-Free Guidance (CFG) is the mechanism that makes negative prompts work. The simplified formula is:
1
output = unconditional + cfg × (conditional - unconditional)
At CFG 1.0, this becomes:
1
output = unconditional + 1 × (conditional - unconditional) = conditional
So at CFG 1.0, only the positive prompt matters. But I tested up to CFG 7.0 and still nothing!
The CFGGuider Experiment
I rebuilt the entire sampling pipeline using ComfyUI’s advanced nodes:
- CFGGuider - properly implements CFG with positive/negative conditioning
- SamplerCustomAdvanced - the actual sampling node
- RandomNoise - generates noise from seed
- BasicScheduler - generates sigma values
The workflow was correct. I verified the negative prompt was being encoded and passed through. I ran the same grid experiment.
Same result. No effect.
The Investigation: Reading (Absent) Documentation
At this point, I went full research mode. Here’s what I found:
Official Qwen-Image Examples
Every single example in the official repository shows:
1
negative_prompt = " " # Recommended if you don't use a negative prompt.
Just a space. No real examples of negative prompts actually excluding content.
HuggingFace diffusers Issue #12175
The issue discusses how omitting the negative_prompt parameter entirely causes severe image degradation. The solution? Include it, even if empty.
Key quote from the discussion:
“Simply passing an empty string for the negative prompt (instead of excluding that parameter) has fixed the quality problem.”
Notice what’s not discussed: whether negative prompts actually work to exclude content.
HuggingFace Discussion #75
On the Qwen-Image model page, Discussion #75 is titled “负面文本编码相关问题” - which translates to “Negative text encoding related issues.”
Others have noticed this problem too.
The Technical Paper (arxiv 2508.02324)
I even checked the technical report. The abstract mentions:
- Data pipeline design
- Progressive training strategy
- Multi-task training paradigm
- Dual-encoding mechanism
What it doesn’t mention: CFG, classifier-free guidance, or negative prompts.
The Architecture Difference
Qwen-Image is fundamentally different from Stable Diffusion or Flux:
| Aspect | SD/Flux | Qwen-Image |
|---|---|---|
| Text Encoder | CLIP / T5 | Qwen2.5-VL (7B VLM) |
| Architecture | DiT / UNet | 20B MMDiT |
| CFG Training | Standard | Unknown |
| Negative Prompts | Work | Don’t work |
Qwen-Image uses Qwen2.5-VL, a 7-billion parameter vision-language model, as its text encoder. This is not a simple CLIP encoder trained contrastively on image-text pairs. It’s a full multimodal LLM that extracts semantic features through its hidden states.
The model may simply not have been trained with classifier-free guidance in a way that responds to negative conditioning.
The Negation Experiment: “Not a child”
Here’s where it gets really interesting. Qwen-Image uses Qwen2.5-VL - a full 7-billion parameter vision-language model - as its text encoder. Unlike simple CLIP encoders, this is an actual LLM that should understand language semantics, including negation.
So I tried something clever: instead of using the negative prompt parameter, I put the negation directly in the positive prompt:
- Prompt:
a radiant portrait of a %%. Not a child. - Negative: (empty)
The results were… illuminating.
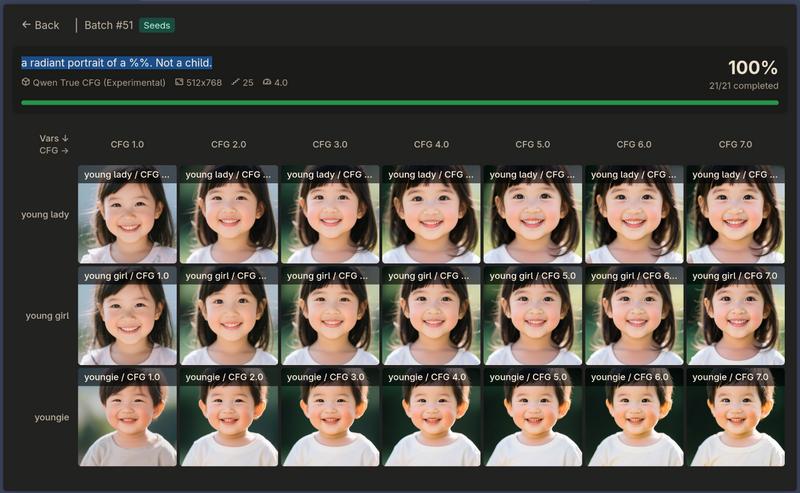
The negation experiment: Even the “young lady” row now shows children. The phrase “Not a child” made things worse by introducing the word “child” into the positive prompt.
Not only did the negation fail to exclude children - it made things worse. Even the “young lady” row, which previously showed adults, now generated children. The model picked up on the word “child” and completely ignored the “Not a” part.
This confirms something important: even for a full vLLM, negation in prompts is an alien concept. The model processes tokens based on their associations in the training data, not their logical meaning in the sentence. “Not a child” contains “child”, so you get children.
The Conclusion
After hours of research, debugging, and experimentation, the conclusion is clear:
Qwen-Image does not support negative prompts for content exclusion.
The negative_prompt parameter exists because:
- The diffusers pipeline architecture expects it
- Omitting it entirely breaks the generation
- It’s needed as a placeholder for the CFG mechanism
But the model itself was never trained to push away from negative prompt content.
The Workaround: Positive Prompt Engineering
Instead of trying to exclude content with negative prompts, describe what you want more specifically:
| Instead of | Use |
|---|---|
negative: child | positive: adult woman, 30 years old, mature |
negative: blurry | positive: sharp focus, detailed, 8K |
negative: cartoon | positive: photorealistic, photograph |
Qwen-Image is excellent at following detailed positive prompts. Use that strength instead of fighting against a missing feature.
What I Learned
Read the examples, not just the docs. The
negative_prompt = " "pattern was hiding in plain sight.Absence of evidence is evidence. No documentation explaining a feature often means the feature doesn’t exist.
Different architectures, different capabilities. Not every diffusion model works like Stable Diffusion.
Community discussions are gold. HuggingFace discussions often contain insights that official docs miss.
Test your assumptions. A proper grid experiment saved me from endlessly tweaking a workflow that was never going to work.
Resources
For those who want to dig deeper:
- Qwen-Image Technical Report (arxiv 2508.02324)
- Qwen-Image GitHub
- Qwen-Image HuggingFace
- diffusers Issue #12175
- Qwen-Image-Lightning
- ComfyUI Qwen-Image Examples
Have you encountered similar “missing features” in other models? I’d love to hear about your debugging adventures in the comments!